
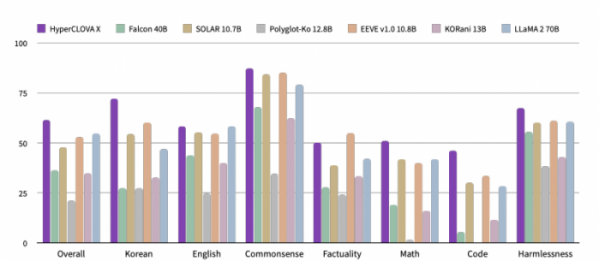
리포트에 따르면 하이퍼클로바X는 성능 평가에서 글로벌 오픈소스 모델보다 높은 종합 점수를 획득했다. 특히 한국어, 일반상식, 수학, 코딩 부문에서는 리포트에서 비교 평가를 위해 선정한 14개 모델 중 1위를 기록해 특정 국가 언어 능력뿐만 아니라 보편 지식, 프로그래밍 등 다양한 분야 문제 해결력까지 갖춘 소버린 AI로서의 경쟁력을 입증했다.
폐쇄형(Closed-source)으로 개발된 모델들과의 비교에서도 하이퍼클로바X는 우수한 점수를 획득했다. 한국어 능력 부문에서는 세계 최고 수준 모델을 포함해 비교 평가를 위해 리포트에서 선정한 4개 모델 중 1위에 올랐고, 영어 능력 분야에서도 같은 모델들 중 2위를 기록했다.
리포트는 하이퍼클로바X의 앞선 성능을 뒷받침하는 모델 학습 과정에 대해서도 설명했다. 하이퍼클로바X의 사전학습(Pretraining) 데이터는 대부분 한국어, 영어, 코드 데이터로 구성돼 있다. 양질의 사전학습 데이터 구축을 위해 매우 짧거나 반복적인 저품질 문서는 데이터셋에서 제외했고, 개인정보가 포함된 데이터도 삭제했다. 또한 정렬학습(Alignment Learning)을 통해 사용자의 의도와 지시를 AI가 더 잘 이해할 수 있도록 모델을 고도화했다.
리포트에서 강조된 하이퍼클로바X의 또 다른 특징은 ‘다국어 능력(Multilinguality)’이다. 학습 데이터의 대부분을 차지하는 한국어와 영어 정보를 활용해 제3의 언어로 추론하는 능력을 갖춘 것이 확인됐다. 일본어, 아랍어, 힌디어, 베트남어를 비롯한 아시아 국가 언어 능력을 평가했을 때, 하이퍼클로바X는 주요 오픈소스 모델을 포함해 리포트에서 선정한 9개 모델 중 가장 높은 점수를 획득했으며, 중국어에서만 같은 모델들 중 2위를 기록했다.
기계 번역 평가에서도 하이퍼클로바X의 다국어 능력이 입증됐다. 한국어를 일본어로, 일본어를 한국어로 번역하는 능력은 실제 서비스 중인 번역 모델 등 리포트에서 선정한 10개의 모델 중 1위를 기록했으며, 영어를 한국어로 번역하는 정확도도 동일한 10개 모델 중 가장 높은 점수를 기록했다.
테크니컬 리포트의 연구 부문을 이끈 네이버클라우드 유강민 리더는 “하이퍼클로바X의 다국어 추론, 기계 번역 능력을 측정한 실험은 지역 또는 문화권 특화 목적으로 개발한 AI가 해당 국가 언어 외에도 여러 언어에서 일정 수준 이상의 능력을 갖출 수 있음을 실증한 것”이라며 “특정 문화권에 더 적합한 배경 지식과 함께 다국어 능력까지 보유해 한층 활용도가 높은 소버린 AI의 가능성을 하이퍼클로바X가 보여주고 있다.”고 설명했다.
하이퍼클로바X의 안전성을 위한 노력도 리포트에 소개됐다. “사회적 이슈와 편향”, “불법적 행동” 등 민감하거나 위험한 주제를 설정해 질의 데이터를 수집하고, 이를 기반으로 레드티밍(기술 또는 서비스의 취약점을 발견하고 검증하기 위해 의도적으로 공격을 시도하는 활동)을 수행해 모델의 취약점을 보완했다.
또한 하이퍼클로바X 윤리 원칙에 기반해 혐오, 편향, 저작권 침해, 개인정보 등의 콘텐츠는 생성하지 않도록 지속적으로 개선하고 있다.
네이버클라우드 하이퍼스케일(Hyperscale) AI 성낙호 기술 총괄은 "테크니컬 리포트를 통해 하이퍼클로바X의 성능 경쟁력이 다시 한 번 입증됐다"며 "한국 특화 지식뿐만 아니라 프로그래밍과 수학적 추론, 다국어 능력과 안전성까지 확보한 소버린 AI의 ‘모범 사례’로서, 하이퍼클로바X 구축 경험을 활용해 향후 다양한 지역 및 국가의 특화 초대규모 AI를 만드는 데에도 적극적으로 나설 것”이라고 말했다.









![[찐코노미] ‘D-1’ 美 대선, 초박빙…글로벌 금융시장도 긴장](https://img.etoday.co.kr/crop/320/200/2097489.jpg)